

How To Build An App Web Crawler Twitter
Crawling Data Twitter Menggunakan Python & Postman
![]()
Data mining merupakan tema menarik bagi saya, sejak tahun 2019 saya sudah mencoba belajar Data Mining, karena memang skripsi saya juga berkaitan dengan Data Mining yaitu tentang Deteksi Hate Speech di sosial media twitter. Sampai saat tulisan ini di buat tesis saya juga berkaitan dengan Data Mining & NLP.
Introduction
Sebenarnya untuk mendapatkan data twitter ada beberapa cara, di antaranya Scraping & Crawling. Untuk perbedaan antara Scraping & Crawling bisa dibaca disini :
Dan pada saat tulisan ini dibuat untuk Scraping data twitter sudah tidak dapat dilakukan, hal itu dikarenakan selector class dan id HTML di Twitter selalu berubah-ubah.
maka alternatif lain kita harus menggunakan Twitter API . Silahkan daftar disini untuk mendapatkan key dan token Twitter API.
Crawling Menggunakan Python
Untuk crawling data twitter kita akan menggunakan library Tweepy . Untuk menginstall Tweepy ada 3 cara
Via pip
pip install tweepy Via clone repository dari github
git clone https://github.com/tweepy/tweepy.git
cd tweepy
pip install Install langsung dari repository github
pip install git+https://github.com/tweepy/tweepy.git saya merekomendasikan menggunakan pip, karena lebih simple. Selanjutnya kita bisa melihat source code dibawah ini.
Sebagai contoh kita ingin crawling data twitter dengan kata kunci python dengan tweet yang dibuat pada antara tanggal 01 januari 2021 s/d 10 januari 2021 dengan maksimal jumlah tweet adalah 100, kita juga akan exluced retweet, sehingga retweet tidak akan di tampilkan. Lalu hasil crawling akan disimpan dengan format .csv
import tweepy
import csv access_token=""
access_token_secret=""
consumer_key=""
consumer_key_secret="" auth = tweepy.OAuthHandler(consumer_key,consumer_key_secret)
api = tweepy.API(auth) # Open/create a file to append data to
csvFile = open('nama-file.csv', 'w', encoding='utf-8') #Use csv writer
csvWriter = csv.writer(csvFile) for tweet in tweepy.Cursor(api.search, q='#Python -filter:retweets', tweet_mode='extended',lang="id", since='2021-01-01', until='2021-01-10').items(100):
text = tweet.full_text
user = tweet.user.name
created = tweet.created_at
csvWriter.writerow([created, text.encode('utf-8'), user])
csvWriter = csv.writer(csvFile)
csvFile.close()
jangan lupa untuk mengisi key & token untuk mendapatkan akses Twitter API. Sebagai informasi untuk paket standar product kita hanya bisa mendapatkan data maksimal 7 hari ke belakang. Untuk mendapatkan data full archive kita bisa upgrade ke premium product dan jika untuk kepentingan riset (mahasiswa) kita bisa mengajukan paket academic research .
Crawling Menggunakan Postman
Alternatif selain menggunakan python untuk mendapatkan crawling data twitter kita bisa menggunakan postman, cara ini terbilang mudah karena tanpa coding, kita cukup menginstall postman dan setup enviroment nya.
Download postman dan enviroment Twitter API V2 disini https://documenter.getpostman.com/view/9956214/T1LMiT5U
Jangan lupa untuk meng-input key, token dan bearer token Twitter API.
https://api.twitter.com/2/tweets/search/all?query= kita akan menggunakan API diatas untuk full archive search, untuk dokumentasi penggunaan Twitter API full archive bisa dilihat disini https://developer.twitter.com/en/docs/twitter-api/tweets/search/api-reference/get-tweets-search-all
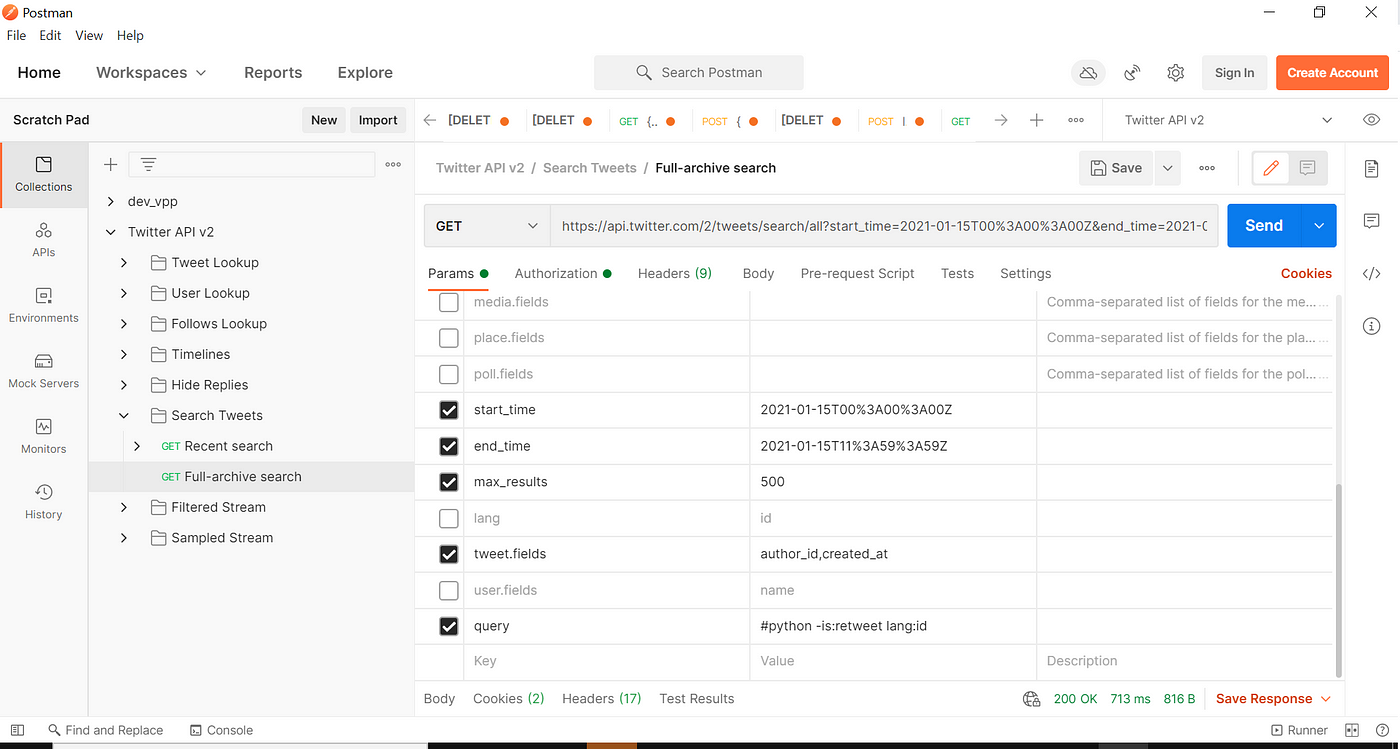
dibawah ini ketika kita ingin mendapatkan tweet dengan kata kunci python. kita input dahulu untuk parameternya.
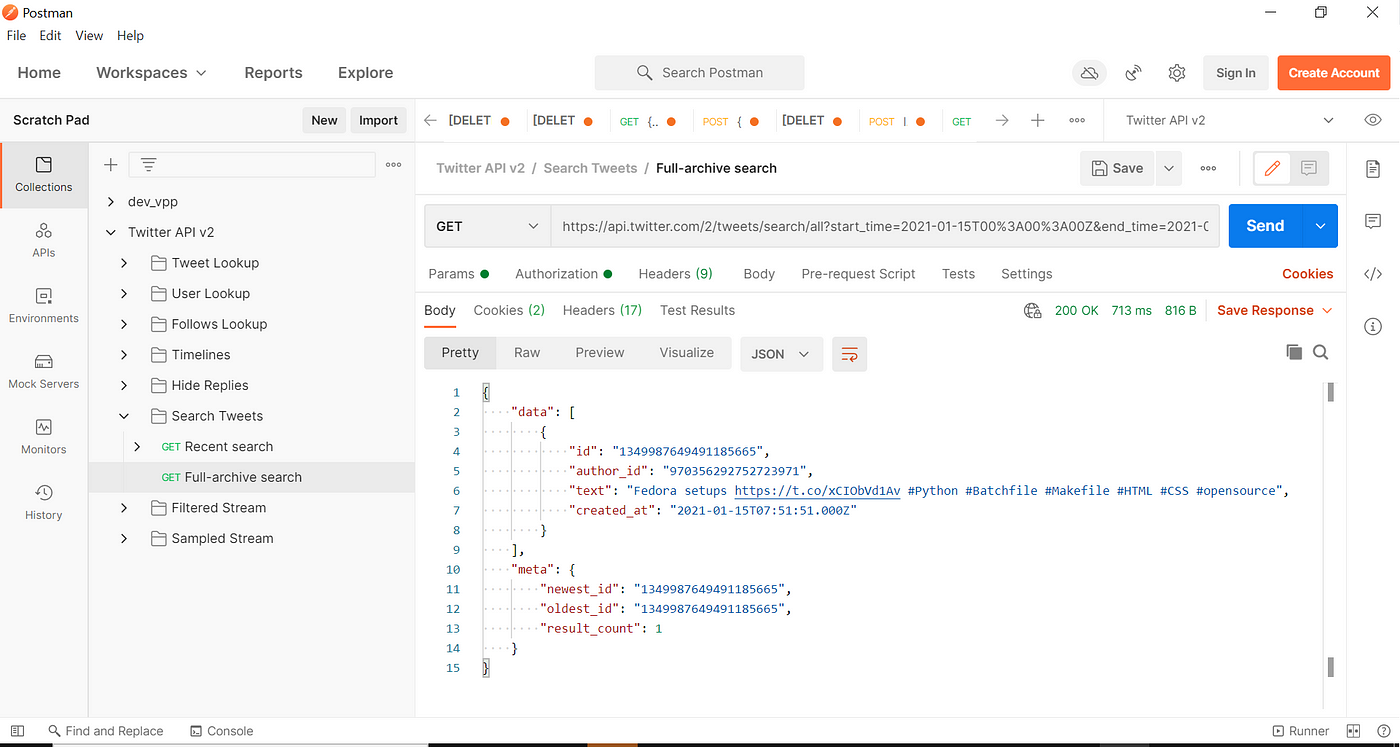
dibawah ini adalah response dari API, kita bisa menyimpan nya dalam bentuk json.
cukup mudah bukan untuk crawling data twitter? Data ini bisa kita manfaatkan untuk berbagai hal misalnya analisis sentimen. Sekian dulu tulisan malam ini, jika ada pertanyaan bisa tulis dikomentar.
How To Build An App Web Crawler Twitter
Source: https://blog.javan.co.id/crawling-data-twitter-menggunakan-python-postman-cffbf14f962c
Posted by: lewislovence.blogspot.com
0 Response to "How To Build An App Web Crawler Twitter"
Post a Comment